概述
在《PTES-渗透测试执行标准》中介绍了渗透测试的一般流程,其中简要介绍了情报搜集的目标。
情报搜集的目标是尽可能多的收集渗透对象的信息(网络拓扑、系统配置、安全防御措施等),在此阶段收集的信息越多,后续阶段可使用的攻击矢量就越多。
因为情报搜集可以确定目标环境的各种入口点(物理、网络、人),每多发现一个入口点,都能提高渗透成功的几率。
情报搜集的方法多种多样,本文主要介绍情报搜集中一些常用的方法。首先对情报搜集的方法进行分类,然后分别从Web应用、主机两个层面对情报搜集的方法进行简要介绍。
分类
根据是否与目标直接交互,可将情报搜集分为被动情报搜集和主动情报搜集。
被动情报搜集
不与目标直接交互;利用OSINT(公开资源情报),通过搜索引擎及其他手段从各种公开的资源中获取目标的信息。
常用工具和技术:Google Hacking、Shadon、Zoomeye、Whois等。
主动情报搜集
与目标直接交互;通过请求响应、扫描等方式获取目标的信息,会在目标服务器留下痕迹。
Web应用
Web应用的情报搜集可以从以下几个方面着手:
IP(IP资产)
渗透测试往往是从Web应用开始,Web应用渗透结束,就会着手主机层面的渗透。要对主机进行渗透,首先得知道主机的IP地址。
对于安全服务来说,客户一般会提供详细的Web资产和主机资产,不需要我们去搜集这些信息;但传统的渗透,这些都需要我们自己去搜集。
获取到的IP信息,首先可用于主机层面的渗透。其次,企业一般都会有一个或多个IP段,或者运用虚拟主机技术,在一个主机上运行多个站点,所以还可用于旁站,C段。
可用于IP信息搜集的工具有:whois、nmap、nslookup等。
子域名(Web资产)
很多时候,渗透测试是从一个域名开始。但一个企业往往会有多个子域名及其他相关业务,就像鹅厂有游戏,有即时通讯等等。
如果只关注一个域名的话,往往会少搜集到很多信息。而且主域名和子域名的关注程度和安全程度可能有所不同,通过子域名枚举,可以发现更多评估范围内的域名,探测到一些隐藏的服务,能够提高漏洞被发现的几率。
可用于子域名枚举的工具有:Google、Sublist3r、knockpy等。
指纹识别(中间件资产)
每件事物都有指纹,根据指纹,我们能得到很多有用的信息。比如,警察搜集指纹,对比指纹库就知道犯人是谁;一看手机logo就知道是什么牌子的手机。
同样,计算机也有指纹。通过指纹识别,我们可以判断目标系统使用了哪些组件,组件的版本等。
指纹识别的一种方式是查看源代码,特别是当系统使用了框架和CMS(内容管理系统)的时候。
框架和CMS一般都会有自己独特的图标、js文件、css文件、版权信息Powered By、标签属性值、注释等等,比如Django框架中,表单默认是带csrf_token验证的,在源代码中我们可以找到隐藏的token字段。
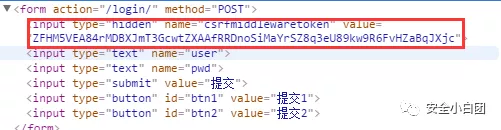
只要我们找到了指纹特征,就很容易判断系统使用的框架,然后去网上查找框架是否有漏洞可利用即可。甚至,还可以下载框架源码去做代码审计。
除了查看源代码,还可以通过与目标交互获取指纹。查看文件后缀,查看目录URL,查看Cookie,查看首部字段X-Powered-By和Server,查看报错页面等等。
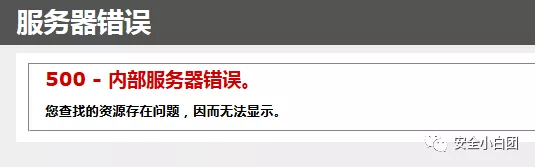
比如我们通过交互,发现这个页面。熟悉的校友应该知道,这是IIS的报错页面,那么操作系统很可能是Windows,因为IIS主要是搭配Windows系统使用。
根据这篇文章,我们可以先存疑,该系统存不存在HTTP.sys远程代码执行漏洞。另外,系统存不存在IIS解析漏洞,解析漏洞又常与文件上传漏洞配合使用,要利用解析漏洞,就要先找到系统的上传漏洞。然后IIS有没有启用WebDAV呢?WebDAV中的COPY/MOVE方法可是不安全的,和PUT方法搭配口味更佳~
哇,感觉世界都是我的了!
总之,指纹识别的目标是:What、Version
1 | 什么服务器,服务器版本 |
源代码
查看源代码还有可能获取到其他敏感信息。
目前绝大多数的网页由3部分组成:HTML(结构)、CSS(样式)、JavaScript(动作),浏览器会将代码解析成对我们友好的页面,但很多细节并不会在页面中展示给我们,比如:隐藏的表单、JavaScript代码等,因此对源代码的审计是很有必要的。
很多校友对源代码的审计可能停留在html文件中,但js文件也需要审计。
一次工作,在js文件中找到了一个积分接口,但页面没有入口。我直接构造url,发起请求,个人账户的积分蹭蹭往上涨。与客户开发人员交流后,得知积分要消费才会涨,积分也可以兑换东西。这个时候就可以将其定义为漏洞了。
目录/文件
在摸清目标资产情况(IP资产、Web资产、中间件资产)之后,我们就可以摸索Web应用的结构了。
在测试大型的系统时,我个人的习惯是先查看一下Web应用整体的功能点和链接结构(接口),然后保证所有的功能点和接口都测试到就行。
因为系统不可能每个链接结构都不一样,一般都会存在复用的情况,除非功能不同。比如充话费,共用一个接口,充值金额不同只要修改接口中的话费id即可。
在测试的时候,我只需要测试其中一种金额就行了,或者测试两种,观察一下其中的规律,看有没有漏洞存在,可千万别1-100块都试一下。如果一顿操作猛如虎,将系统中所有链接都一个个去点击抓包分析,效率往往会低很多。
如何查看链接结构?我们可以把鼠标移动到要点击的链接上,浏览器下方会显示出来,或者点击链接,查看浏览器地址栏中的URL,或者抓包,这些方法都可以。

以上是摸索Web应用结构的一种情况,能提高我们渗透的效率。还有一种情况,就是查看特殊的目录和文件。
何为特殊的目录和文件?
1 | 网站后台:/admin、/manage、/wp-login.php 等 |
要查看这些目录和文件,有两种方法:一是手工构造,利用自身经验以及之前搜集到的信息,构造路径,查看目录和文件是否存在;二是利用字典跑出来。搜集这些目录和文件有什么用,应该不用我说明了吧?
可用于目录/文件搜集的工具有:Burpsuite、DirBuster、google等。
邮箱/电话/工号/…
几乎所有的网站都存在登录功能。要想登录系统,两种办法:一是利用其他漏洞登录,二是老老实实输入账号密码。
第二种方法也包含两种情况:暴力破解、明确获取到账号密码,这都涉及到邮箱/电话/工号等信息的搜集。
如果明确获取到了账号密码,这当然是幸运的;如果没有明确获取到账号密码,我们也可以根据搜集到的邮箱/电话/工号等信息,去发现命名规律,然后生成字典去爆破。
去年在给联通还是电信某个系统测试的时候,登录页面明确提示使用工号登录,查看系统相关源码,没有发现工号的踪影。我在网上查了一下,工号是4位数,然后利用登录页面的用户枚举漏洞,使用burpsuite的Intruder模块,从1111-9999中获取到了几个系统存在的账号,然后利用字典爆破出了密码,使用的是弱密码,可能是测试账号忘记删除了。如果不仔细搜集信息,使用字母字典或者不是4位数的数字字典,那可能永远都跑不出账号。
可用于邮箱信息收集的工具有:whois、The Harvester等。
github
作为全球最大的“同性社交”网站,github包含了海量的信息。这些信息中,不乏大量的“个人社交”信息。
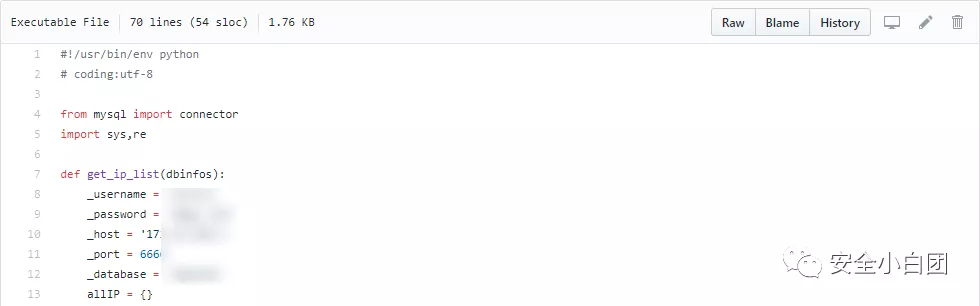
鲁迅说过:“朋友多了路好走”。当你无路可走的时候,不妨出来交交朋友。像上面的截图,用户名、密码、IP地址、端口、数据库名直接告诉你,都不需要去SQL注入,一条明路就这么出现了。
当然,除了github,还有其他“社交”网站:gitee、coding等。
主机
相对Web应用,主机层面主要关注端口开放情况以及端口banner。
服务器通过不同端口向用户提供不同的服务,服务器就像一座房子,而端口就是一扇扇门,通过门进出房间(请求与响应),不同的门对应不同的房间。
每多开放一个端口,就多开一扇门,小偷打开门进入房子的成功率就高一分。当然,小偷需要开锁才能打开门,该用什么方式开锁,取决于锁的种类以及锁的安全级别,这些都能在端口号和端口banner中获取。
端口
每台服务器都有65536个端口,端口号范围:0—65535。不同的端口对应不同的服务:
1 | FTP : 21 |
有一定基础的校友看到这些端口,应该能明白我想表达什么:FTP匿名登录、SNMP弱口令、给我哭、未授权、未授权、DRDOS。
设想一下,你在给客户测试准备上线的管理系统,你测试了半个月,Web应用竟然没任何问题。你:开发人员真棒,上线吧。结果上线5分钟,挂马2000个,检查发现上面那些端口服务器都开放了且都是默认配置。根据《网络安全法》,你可能需要喝几杯茶。
简单的举例,大家应该能明白全面搜集信息的重要性,这也是我将情报搜集分Web应用和主机两个层面的原因,主机端口扫描能帮助我们发现更多可行的攻击途径。当然,端口漏洞远远不止这么点,需要靠校友们不断的去储备知识和积累经验。
可用于端口扫描的工具:nmap、nessus、shodan、censys.io等。
Banner
通常情况下,端口扫描不仅能获取到服务器的端口开放情况,还能获取到端口banner信息。
通过banner信息,可以获取到服务器操作系统以及运行在其开放端口的服务的信息,包括正在运行的应用程序以及操作系统的版本。
获取到版本有什么用呢?这就要借助互联网的力量了。互联网上有各种信息,漏洞信息也不例外,特别是各大安全站点,往往会有漏洞的详细信息,poc、exploit等。
获取到版本信息后,我们可以在网上查询该版本的软件和操作系统是否有已公布的漏洞,是否有poc和exploit,进而去验证和利用漏洞。
可用于banner获取的工具:telnet、nmap、netcat、shodan、censys.io等。
结语
情报搜集的方法和技术远远不止这些,一篇文章是介绍不完的。这里我只是简单的介绍情报搜集的一些思路,起到一个抛砖引玉的效果,希望校友们能够发散思维,形成自己的一套搜集方案。
篇幅问题,细节不再深究,后续我再一个一个给大家讲解。不要小看情报搜集,组合发散延伸,会让你在渗透后续阶段如虎添翼。
免责声明
安全小白团是帮助用户了解信息安全技术、安全漏洞相关信息的博客。安全小白团提供的程序(方法)可能带有攻击性,仅供安全研究与教学之用,用户将其信息做其他用途,由用户承担全部法律及连带责任,安全小白团不承担任何法律及连带责任。
